
缓存穿透
概念: 查询一个数据库中也不存在的数据,数据库查询不到数据也就不会写入缓存,就会导致一直查询数据库
解决方法:
1. 缓存空数据
如果数据库也查询不到,就把空结果进行缓存
缺点是 - 消耗内存
2. 使用布隆过滤器
布隆过滤器的作用 :检索一个元素是否在某个集合中
布隆过滤器由组成 : 位图 + 若干哈希函数
位图: 一个以 bit (位) 为单位的数组,数组中的每个单位只能存储二进制数 0 或 1 ,并且在初始状态下都为 1
比如数据库中有个 id=1 的数据,布隆过滤器会通过三个哈希函数分别计算出其哈希值为 1 、3 、7 ,将这三个位置的值置为 1
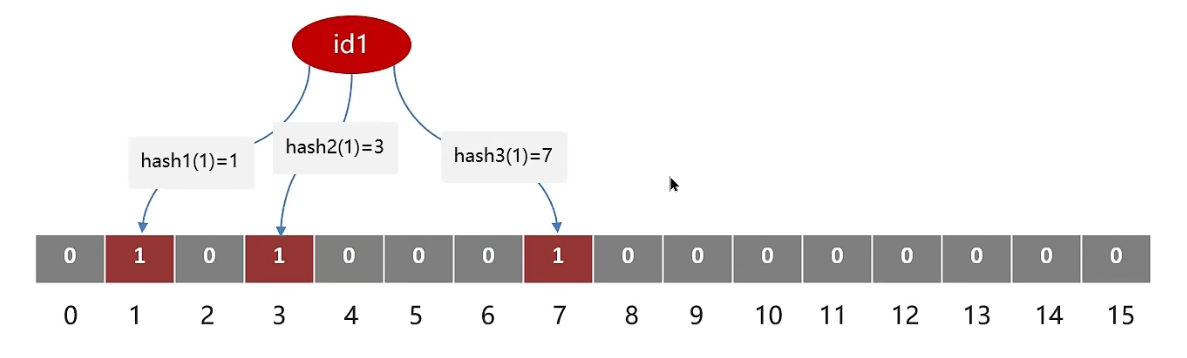
接着依次将数据库中的其他数据按照该方法写入布隆过滤器
如果此时请求查询 id = -1,根据那三个哈希函数计算得到的哈希值为 1 、 3 、 14 ,并且位图中 14 位置的值为0, 那么我们就可以肯定这个数据在MySQL中不存在
但如果 计算出来的值是 1 、 3 、 14 ,且这三个位置的值都为 1,那也不能确定 id=-1 的数据在数据库中存在,比如以下情况

1 、 3 、 14 三个位置的值都为 1 ,并不是因为 id=-1 的数据存在,而是恰巧 id=1 和 id=2 的存在使得 1 、 3 、 14 三个位置的值都为 1
我们可以想到,数组越小,误判的概率就越大,上面的位图只是做演示,实际上的位图长度非常长
在 Java 中提供了具体的实现方案 Redisson 和 Guava
布隆过滤器的预热 和 缓存的预热是在同一时刻进行的,之后的请求都会先打到布隆过滤器上,如果布隆过滤器判断该数据不存在直接返回,如果判断存在再放行查询缓存
缓存击穿
*概念:*一个非常热点的key在扛着大并发,当这个key过期的时候,持续的大并发就穿破缓存,直接打到数据库上,把数据库压垮
解决方法:
添加互斥锁(分布式锁)

当 线程1 查询缓存未命中时,添加一个互斥锁,接着查询数据库重建缓存,重建缓存的过程中,又来个 线程2 ,线程2 也不会命中缓存,那么 线程2 会尝试获取互斥锁,但是失败(因为此时被线程1持有),线程2 会休眠一会儿重试,直到 线程1 重建缓存成功,线程2 N次尝试后命中缓存
实例代码如下:

逻辑过期
概念: 对热点数据不设置过期时间,我们在写缓存的时候添加一个过期时间字段
其执行过程如下

线程1 查询缓存,发现数据已经逻辑过期,则获取互斥锁,并创建子线程 线程2 去重建缓存,然后直接返回过期的数据,在 线程2 重建缓存的过程中,又来个 线程3 发现缓存也过期了,而获取互斥锁失败,同样直接返回过期数据
两种方法的比较:
- 互斥锁 -- 能保证数据的强一致性 但是 性能较差
- 逻辑过期 -- 优先保证高可用,但是数据一致性较差
现实开发过程中,要根据不同的业务场景进行选择,如果业务中设计金钱交易,一般要保证高可用,选择互斥锁,而在互联网的场景中,更加注重用户体验的场景,首选逻辑过期方案
缓存雪崩
概念: 在同一个时段内,有大量的key同时失效 或者 Redis服务器宕机,导致大量请求到达服务器,带来巨大压力
解决方法:
如果是有大量的key同时失效 -- 给不同的key的过期时间添加随机值
如果是Redis服务器宕机 -- 搭建Redis高可用集群
兜底方案 -- 给缓存业务添加降级限流策略
对于这三个问题,都可以使用 降级限流策略 解决,但是降级限流会影响用户体验


评论